
Dealing With AI Biases Part 3: Emergent Biases in Operational Models
The AI bias problem is often treated as a data problem, because many well-documented examples of biased AI behaviors are inherited directly from the biases within their training data.
As we discussed previously, biases in data are not always bad. In fact, data scientists often inject biases as the data is being preprocessed before training. Bias injection can be used to counteract unwanted biases that result in unfair treatment, discrimination, or marginalization of subpopulations defined by immutable characteristics.
Today, we are going to explore another important class of AI biases. These are emergent biases that are not inherited from the training data. That means these biases can still emerge even when we have trained the machine-learning (ML) algorithms with a cleansed data set with no known biases. To see how this is possible, we must understand where emergent biases originate.

The Origin of Emergent Biases
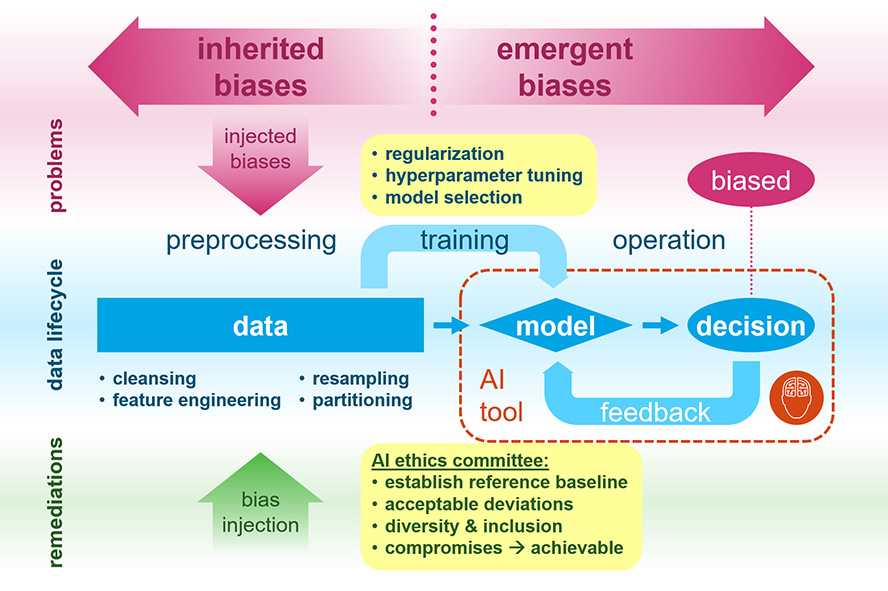
A stereotypic data science workflow involves:
- Preprocessing the data given to data scientists
- Training the ML algorithms to obtain the final model
- Deploying the trained model in production AI systems
Although this stereotypic workflow is highly simplified, it does offer some insight into where emergent biases might crop up. First, we must recognize that during the model deployment phase (step 3), the model and all its artifacts (e.g. parameters, configs, auxiliary files, and libraries) are fixed and not supposed to change. The deployment process simply replicates the computing environment on the cloud and transfers only the required assets for the model to execute on the cloud. Therefore, it’s unlikely that biases could be introduced during deployment.
Moreover, if data preprocessing (step 1) is done right, there shouldn’t be any unwanted biases in the training data. Since emergent biases are not inherited from the training data, the only place these biases could emerge is during the training process (step 2). Therefore, it’s time for us to dive in and see what could have created emergent biases during the training process.
Despite common belief, the ML training process is a highly nonlinear process that involves many iterations of re-training and re-testing. Since this subject is highly technical, we will gloss over the details and focus our discussion instead on the context of bias creation and provide links for deeper exploration.
Training ML Models Under the Hood
As a data scientist, when we say we’re training an ML model, what we’re really doing is optimizing some objective functions (or loss function) with respect to the model’s parameters. Simply put, we want to find the model parameters that optimize the objective function, which usually measures how well the model fits the data.
There are a handful of standard objective functions (e.g. squared loss, log-likelihood loss) for common types of ML problems (e.g. regression, classification), respectively. But, beyond the most common ones, there are many more objective functions considering all the specialized applications of ML.
Choosing one objective function over another is more art than science, as each one makes certain assumptions about the noise in the data. In practice, most assumptions about the data are far from accurate, let alone the assumptions about noise hidden inside the data. And when these assumptions aren’t met, the optimized model parameters will be biased, resulting in a biased model. A textbook example of this is when training a regression model using the squared loss. The optimized model will be heavily biased by the presence of outliers.
Detecting Emergent Biases
The output of the training process is the model. Because the training process only focuses on optimizing the objective, there is no restriction on how it transforms the training data. Therefore, it’s possible that the training data may be transformed and recombined to create emergent biases in the model.
It’s important to note that detecting emergent biases is much more challenging than detecting inherited biases. First, analytics of the AI’s decision must be analyzed to see if all the biased AI decisions can be explained by known biases within the training data. Emergent biases are those that cannot be explained by biased training data.
However, since these biases are encoded deeply in the numerous parameters and hyperparameters of the model, it’s very difficult to uncover emergent biases by examining the model. In practice, many of the trained models are not even interpretable, so the only effective way to detect emergent bias is through continuous monitoring of the model in operation.
Furthermore, AI bias is never apparent when examined individually. Just as it’s impossible to determine if a coin is fair by observing just a few coin flips, AI bias can only be observed when we have a statistically significant sample size of decisions. Therefore, it’s crucial to track the decision output of all AI systems over long periods of operation and have an AI ethics committee periodically audit the AI’s decisions against pre-established compliance.
Building an AI Ethics and Integrity Committee
An important function of the AI ethics committee is to establish these compliances. If you’re part of an AI ethics committee for an HR AI system, for example, you’ll need to first establish the reference baseline for the AI to be fair (unbiased). Should you use the demographic distribution for the country as a baseline? What if this system is used in a city where the demographic differs significantly from the national level? Or should you just use the current, recent, or also past job applicant’s demographic distribution as a reference?
Besides establishing the reference baseline, the ethics committee must also determine the acceptable deviation from the baseline. Since any finite number of coin flips will deviate from the 50% head vs. tail baseline (sometimes quite significantly under a small sample), such deviation is purely a result of random sampling, not bias. Determining the acceptable range of deviation requires both statistics and industry domain knowledge.
In practice, ethical compliances are usually not striving for 100% unbiased decisions. Rather, it’s a balance between the current status and something aspirational. In fact, they’re more achievable and therefore more effective long-term when created by a committee with diverse members. Moreover, having many pairs of eyes with different lenses helps the committee better scrutinize the analytics on the AI’s decisions and be more effective in identifying new biases before they turn into crises.
The Two-Edge Sword: Creating Bias to Fight Bias
Just like inherited biases, which can be injected into the training data, biases can also be introduced into the training processes. Besides choosing the objective function, data scientists have several additional mechanisms to inject bias into the ML model through training. Because these techniques all involve some degree of subjectivity, I will collectively refer to them as subjective model selection methods.
- Regularization: Adding regularizer terms to the loss function to impose additional constraints on the model (e.g. in ridge regression, lasso regression, and early stopping)
- Hyper-Parameter Tuning: Choosing the structural or higher-level parameters that are not being fitted when optimizing the objective function (e.g. cross validation, Bayesian optimization, and evolutionary algorithms)
- Complexity-Based Model Selection: Balancing the complexity of the model by penalizing its degrees of freedom using information-theoretic criteria (e.g. AIC, BIC, and MDL)

It’s not news in data science that subjective model selection will produce biased models. But these biases are typically statistical in nature and won’t result in unfairness or discrimination. By using these techniques, we can nudge the model to put more weight on variables with certain statistical characteristics when generating its final decisions; thus, biasing the model. Yet, we use these techniques regularly to improve model performance on unseen data by mitigating overfitting, which ultimately makes the model more robust and generalizable.
Now, it’s precisely because subjective model selection can create bias in models that we can sometimes use them to create the biases we want, in order to counteract those we want to eliminate. However, this is a double-edged sword and must be done carefully. Otherwise, we could be introducing more biases than we remove. In fact, it’s likely that many emergent biases were accidentally created through the careless application of these techniques.
Injecting Bias Properly: Beware of Correlation
So how do we inject bias properly and safely?
Recall that subjective model selection techniques will bias an ML model’s output decision based on certain statistical characteristics. Therefore, it’s crucial to ensure these statistical qualities are not correlated (with any statistical significance) to sensitive or protected demographic traits. Otherwise, the biases injected through subjective model selection may also be biased with respect to demographics.
Establishing a significant correlation between demographics and some statistical properties of interest is very hard. Because these correlations are usually very weak, and they could arise purely from the randomness of finite sampling. Alternatively, such weak correlations may reflect a weak but causal relationship that is far upstream on the chain of causality.
The challenge is that there is currently no effective way to determine which cause produced these weak correlations. Therefore, despite all the scientific rigor that goes into bias mitigation, dealing with emergent biases still requires substantial human interventions.
Conclusion
Even when the training data is unbiased according to the established compliances, emergent biases can still be created during the training process. This can happen if we fail to establish the causal correlations between sensitive demographic traits and the statistical properties we used in subjective model selection.
Due to the difficulty in determining such causal relationships, emergent biases can only be uncovered through long-term tracking of the AI’s operational decisions and periodic audits by a diverse ethics committee. But once identified, emergent biases can be corrected by injecting counteracting biases into either the training data or during the training process.
DISCLAIMER: The content of this article was first published by CMS Wire. Here is the latest revision and a current rendition of the raw manuscript submitted to the publisher. It differs slightly from the originally published version.