
Dealing With AI Biases Part 2: Inherited Biases Within Your Data
Today, AI technology is becoming more pervasive in our lives. But one major roadblock is still preventing enterprises from realizing AI’s full potential. The fear and distrust of AI because AI can be biased is still preventing many industries from fully embracing AI and its many benefits.
Previously, we talked about the AI bias problem and explored how AI became biased. And the simplest response to AI bias is to acknowledge the bias and use the trained algorithms judiciously. Not using the biased AI in populations where its bias marginalizes certain groups could limit its potential damage, but this also limits its benefits.
So, what more can we do to deal with AI bias?
As discussed in the previous article, the AI bias problem is currently being thought of as a data problem. And to a large extent, if we can fix the biased data, we would’ve addressed most of the AI biases. Before we attempt to correct the bias in data, we must first clarify a common misconception about bias.
Biases in Data Aren’t Always Bad
Contrary to most common beliefs, not all biases are bad. In fact, biases are often introduced in training data to improve the performance of the trained model. The classic example of this is when training a classifier with imbalanced data (i.e. using data with highly skewed class proportions).
If we are collecting transaction data from an e-commerce portal to train a fraud detector, we will get a lot more legitimate transactions than fraudulent ones. This imbalance in the labeled data is an unbiased representation of reality and reflects the natural occurrence rate of fraud. Although highly undesirable, fraudulent transactions are pretty rare.
However, it’s a common practice in data science to resample such data to achieve a more balanced class proportion (i.e. ~50% legit and ~50% fraud) before training. By doing so, we are introducing bias into the training data. The result is that we will make the classifier much more sensitive to detecting fraudulent transactions (i.e. more discriminant). It could be argued that we are in essence discriminating against the fraudster. But wait, isn’t that exactly what we wanted?
Clearly, the bias, in this case, is desirable. And in many situations, data scientists might introduce biases artificially to make machine learning (ML) more effective, to make use of their limited data more efficiently, or simply to make the model perform better.
So when is bias undesirable? When it marginalizes certain groups in a population where the AI will be used. Some of the worst kinds of AI biases are those that result in discrimination and marginalization of certain groups defined by protected characteristics, such as race, gender, age, etc. Such biases are definitely unwanted.
Now that we understand what kinds of biases are undesirable, we can examine how to correct these unwanted biases in our data. When we talk about biases in the rest of this article, it’s assumed that they are unwanted biases unless stated otherwise.

The Origin of Inherited Biases in Data
AI can inherit the biases in its training data. And these biases could arise anywhere along the data processing pipeline from the moment the data is captured. This biased data is usually a result of two processes.
- Some biases may be inherent to the data collection processes
- Other biases may be introduced as part of the preprocessing and feature engineering processes.
However, in most data science work, we typically don’t control the data collection process. Data scientists simply work with the data they have as is. So, in this article, we are going to defer data capture biases to a later discussion and focus on the injected biases during the data preprocessing phase of the ML pipeline.
Avoiding Inadvertent Bias Introduction
As stated earlier, it’s common practice for data scientists to do some data wrangling before using them to train the ML models in AI. And there are literally an infinite number of ways that we can cleanse, transform, and enrich the raw data in the preprocessing stage before training. This includes resampling the data to achieve a more balanced class proportion, feature engineering, and even how we split the data for training and validation.
During this data preprocessing stage, it is possible to accidentally introduce unwanted biases into the data. How can we prevent this? Ironically, the best way to prevent the accidental introduction of bias is to have detailed demographic attributes (which include the protected characteristics) for all the data elements. This enables data scientists to monitor the distribution of the demographic attributes and see how they’ve changed as the data is preprocessed. Without the demographics, we simply can’t be 100% sure that no bias was introduced through data wrangling.
Due to the sensitivity and risk associated with detailed demographic data, however, many organizations are choosing not to capture or store them. In the absence of demographics, the standard approach to avoid creating bias is to leverage randomness. If a sufficiently large sample is selected completely at random, then it should not change the underlying distribution of the population’s demographics. Although we can’t be sure, at least we’ll have deniability if bias was inadvertently introduced.
Collecting Sensitive Demographic Data
Since AI can inherit its biased behaviors from its training data, it’s obvious that we should never use any data or features derived from any protected characteristic under local laws. Moreover, these protected characteristics may be different in different countries. However, this doesn’t mean that we should never collect any demographic data.
Having detailed demographic data can help reveal the biases in the data so we can better understand them. However, having the demographic data within easy reach of data scientists is a temptation. So should you collect sensitive data with protected characteristics?
The answer depends on the maturity of your organization’s data practices. In established data enterprises with strong data governance, where access to every piece of data is logged, reviewed and scrutinized, collecting demographics can actually help monitor and prevent injecting biases. But in a startup where anything goes, it might be safer not to have such demographic data at all to prevent accidental misuse.
Regardless of whether you have access to demographic data or not, you should never use it, or any derivative of it, to train your ML models!
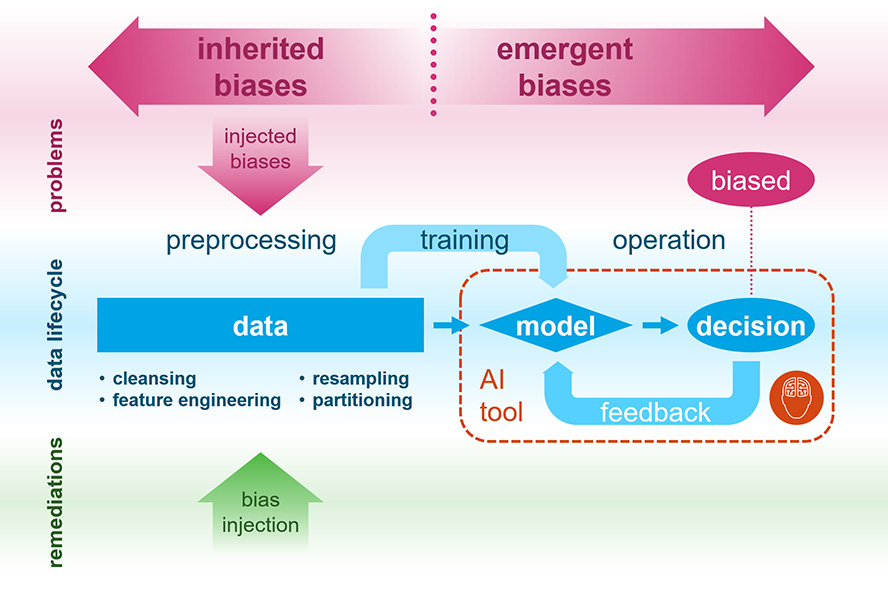
Injecting Bias into the Training Data
Finally, another ironic fact in dealing with AI bias is that you can fight bias with bias in some situations. Since we can artificially introduce bias into the training data as we preprocess it for training, we can inject good biases to counteract the unwanted biases. And we have already seen it in action when we discuss why biased data aren’t always bad.
Let’s say we are building an English speech recognition system, and we have collected random speech samples in the US to train this system. If the sampling was truly random across the entire US, then the ethnic distribution of the data should reflect the underlying demographic of the US population (i.e. ~60% White, ~19% Hispanic, ~12% African American, and ~6% Asians).
Although this is an unbiased representation of the population, training our system with this data could potentially make the system exhibit biased behaviors. For example, the system may perform poorly and couldn’t recognize speeches from users with Asian accents. This is a direct consequence of not having enough training samples for the ML algorithm to learn the Asian accents. Although there will be a lot fewer Asian using this system since there are only 6% Asians in the US, we want this system to perform equally well (be unbiased) for all users within the US.
In this situation, we can inject bias into our training data by subsampling the training data from White, Hispanics, and African Americans, to artificially increase the proportion of training samples from Asian speakers. Essentially, we are injecting bias into the training data to reduce our AI’s performance bias across a protected characteristic (i.e. race).
Conclusion
So not all data biases are bad. In fact, “good bias” in data is often introduced deliberately to make ML more effective, use the limited data efficiently, or counteract the negative effects of “bad biases.”
When dealing with AI biases that are inherited from its training data, it’s helpful to have detailed demographic attributes for the training data samples. It allows better acknowledgment of biases (which includes long-term monitoring and reporting). However, working with sensitive demographic data that contains protected characteristics is not without risk. And it’s best to have a matured data governance function before diving in.
In the next installment of this mini-series on AI bias, we will explore how to deal with emergent biases that are not inherited from the training data.
DISCLAIMER: The content of this article was first published by CMS Wire. Here is the latest revision and a current rendition of the raw manuscript submitted to the publisher. It differs slightly from the originally published version.