
Dealing With AI Biases Part 4: Fixing the Root Cause of AI Biases
We took a short digression last week. But today, we are going to discuss the final battle in dealing with AI bias. That is, how can we fix the root cause of AI biases? Since today’s exposition builds on our previous discussions on this very topic, it’s important to get familiar with the 3 installments we’ve already published on AI bias.
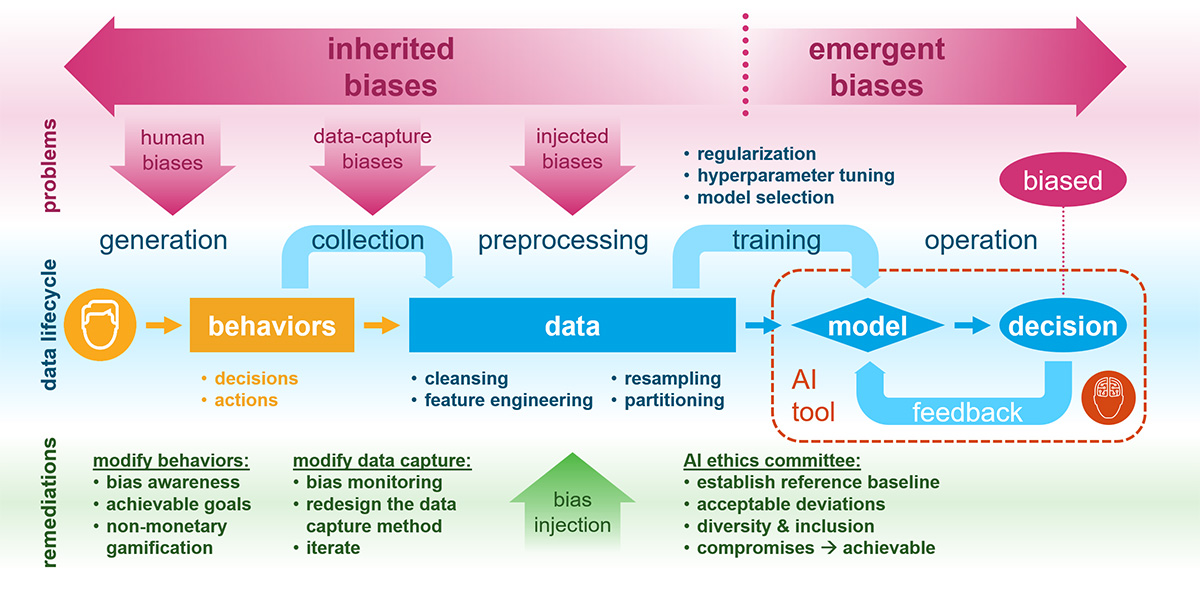
As previously discussed, the most common sources of AI bias are those inherited from training data. And these inherited biases are often introduced as we preprocess the data before training. On the contrary, emergent bias can be created during training even when the training data is unbiased. So these biases are often created during training as data scientists employ subjective model selection (e.g. regularization, hyperparameter tuning, etc.) to finalize their model choice.
Contrary to conventional belief, data science work requires much discretion. Hence, many standard procedures in data science are potential sources where bias can be introduced if applied haphazardly. But they also serve as natural points for us to inject counteracting biases to neutralize the biases we want to eliminate. With meticulous data scientists, inadvertently injected bias (whether inherited or emergent) should be minimal. What’s left are the inherited biases that already exist in the training data.
As data scientists, we often treat the data given to us as the raw input. We seldom question where the data came from and how it was collected. Where did these pre-existing inherited biases come from, and can they be eliminated? In most practical situations, there are two root causes where inherited biases originate.

Data Capture Biases
Since all training data must be captured and collected at some point, pre-existing inherited biases may be a result of biased data collection processes. All data collection schemes are designed and built as a result of a series of design choices. And it’s a well-known fact in Choice Architecture that there are no neutral designs. Hence, every data collection process is inherently a little biased.
For example, it’s common knowledge that survey data always exhibit a certain self-selection bias. Such data will over-represent the already inclined and diligent consumers and under-represent those that are either lazy or paranoid.
We may still be biased even when the data is collected automatically through passive behavior monitoring via sensors, devices, or WiFi networks. We may inadvertently be selecting the population that is near the sensors we installed. And we may systematically under-represent those who don’t have access to reliable WiFi or a mobile device.
If we don’t control the data collection process, which is typically the case for most data science work, it’s still important to understand the data collection processes to understand the biases inherent to the data collection process. We need to acknowledge these biases as we’ve discussed in my previous article. In practice, this means we must continuously monitor the level of bias in the captured raw data to ensure changes in bias do not adversely impact the trained model.
However, in some rare situations where we can influence the data collection process, we should aim to capture more data and more complete metadata that provides the context to interpret those data. In the age of big data and ubiquitous sensors, the default strategy should be to collect everything possible.
“Debating over what to collect often ends up being more costly due to lost time and development velocity.”
Andreas Weigend, former Chief Scientist, Amazon
Having detailed demographic data can help reveal the biases inherent to the data collection process so we can better understand them. It will facilitate the effective monitoring of how data-collection biases change over time. Most importantly, it can also help us redesign the data-capturing process to reduce bias during data collection. As with any design, redesigning the data-capturing method is an iterative exercise. With proper bias monitoring and rapid iteration, data-collection biases can be progressively minimized over time.
Unconscious Human Biases
If the data-capture mechanism has been iteratively perfected, the only place where inherited biases can be created is during data generation. But most of the data used in training machine-learning (ML) models are generated by humans. These data are merely the result of past human decisions and behaviors. Therefore, the inherent biases in the training data originate from us, humans. The bias in data is simply a reflection of our own bias.
In practice, however, AI bias often appears to be more extreme and therefore more noticeable than our own bias. This is because the slightest bias in our decisions can often be magnified dramatically through the ML training process. Our minute biases are accentuated when machines learn from large amounts of data very rapidly. This amplification is a result of both the high speed of learning and the consolidation of lots of data. Despite this, the AI bias problem is fundamentally a human bias problem.
Solving for AI Bias
Now that we have a good grasp on the root cause of the AI bias problem, how can we solve this problem?
As with most problems, recognizing the problem is half the battle. The other half of the battle involves human behavior change. Fortunately, this is a problem we know how to solve. And the solution involves 3 steps:
- Provide analytics to drive awareness of existing human biases
- Set small but incremental goals toward bias mitigation
- Use gamification with non-monetary rewards to motivate less biased decisions
A Hypothetical Root Cause Solution in HR
Rather than discussing this solution in the abstract, it’s instructive to examine an example in HR, where AI bias in hiring is well documented. Due to statistical randomness, even a perfectly fair coin may appear biased when the number of observed coin flips is small. Likewise, bias in hiring is often not noticeable when examined over a short timeframe (e.g. 1 month or 1 quarter) due to the small sample size.

Therefore, it’s often helpful to provide analytics and reports on new hire demographics over the entire year and even across multiple years. This allows a hypothetical engineering hiring manager to get a more complete picture of the hiring biases committed within the entire engineering department. Although this hiring manager might have only hired 1 male engineer last quarter, seeing that the last 15 engineering hires over the last year have all been males will likely influence his decision on the current candidates.
Given this imaginary engineering team is so male-dominant, it is unproductive to set an unrealistic goal of getting to a balanced engineering demographic. If the current male-to-female ratio is 10:1, it will be more helpful to set an achievable goal of getting to 9:1 rather than 1:1. Rather than striving to hire 15 female engineers this year, it’s more helpful to aim at hiring 1 or 2.
Once the easy goals are achieved, it’s important to stretch these goals over time toward a well-balanced demographics. Perhaps next year, the goal is to achieve an 8:1 male-to-female ratio, and they should strive to hire 3 or 4 women in engineering.
Setting achievable diversity and inclusion (D&I) hiring goals is helpful and often necessary for team alignment. However, humans often need a little nudge to effectively change our behaviors. Gamification is a highly effective tool that uses behavior metrics to motivate the desired behavior through a hierarchical system of incentives strategically delivered over time. Although monetary incentives work well short term, it’s not an effective driver for long-term behavior change in practice. So, it’s important for leaders to creatively institutionalize awards and recognitions that motivate the desired D&I hiring behaviors that will eventually change the company’s culture sustainably.
Conclusion
Although there are emergent AI biases that are created through the training process, most AI biases are inherited from its training data. So where did these inherent biases in training data originate?
- The data is captured with biased data collection mechanisms
- The data is generated from biased human decisions and behaviors in the past
The data capture biases are often dealt with through iterative refinement of the data collection processes while we carefully monitor the biases. Interestingly, unconscious human biases can also be dealt with pretty much the same way.
By monitoring our own biases and iteratively influencing the biased human behaviors that generated the training data, we, humans, can also learn to make decisions that are less biased, eventually. Thus, learning how to fix AI biases not only improves our AI tools, it can also improve ourselves and make us better humans.
DISCLAIMER: The content of this article was first published by CMS Wire. Here is the latest revision and a current rendition of the raw manuscript submitted to the publisher. It differs slightly from the originally published version.